
Intel’s New GPU: Xe3 Structure Modifications, Handheld Gaming CPUs, & XeSS3

The largest change to Xe3 is that it’s simply bigger, with render slices scaling as much as extra Xe cores per slice, a rise in L1 cache from 192KB to 256KB, a big enhance in L2 cache, and extra registers which can be higher utilized.
Micro benchmarks present important enhancements in occluded primitives culling for pointless triangles when rendering sport scenes along with enhancements in anisotropic filtering.

Its variable register allocation and register modifications additionally intention to unclog the pipeline in order that the {hardware} might be higher utilized, as one of many largest issues with Arc in its present Xe2 and Battlemage implementation has been that there’s loads of {hardware}, nevertheless it’s not getting used correctly. This can be a mixture of each {hardware} points, like with fastened perform models within the structure, and driver points, which it has been slowly addressing. A few of this included shifting off of emulation of issues like execute oblique beforehand to eradicate overhead.
For Xe3, Intel famous to us a few of its driver enhancements and software program management panel focus as properly, all of which ought to profit the corporate because it strikes towards its eventual dGPU Celestial GPUs.
This accompanies quite a few different bulletins associated to its Panther Lake cell options and laptop computer {hardware}, plus some “AI” and NPU {hardware}.
We’re largely going to give attention to the IP block of Xe3 and the structure and gained’t be as targeted on the product aspect for laptops.
Though this isn’t a dGPU half, it’s probably that this method will both be instantly discovered within the subsequent dGPU or will not less than point out which path Intel goes.
Intel was clear that this isn’t precisely Celestial, which is the structure following within the Alchemist – Battlemage – Celestial – Druid lineup. Intel famous that “Xe3P” will observe Xe3. The “P” unironically stands for “Plus,” displaying previous Intel habits die laborious. Intel didn’t affirm this, however the impression we received is that Xe3P would be the “actual” Celestial GPUs, whereas this Xe3 makes main modifications that probably set the stage for it.
Overview of Bulletins
Intel had plenty of bulletins to share with the press for at this time. For our protection, we’re focusing nearly totally on the Xe3 modifications and micro benchmarks. We’ll cowl among the different information as properly, like efficiency/Watt enhancements and XeSS modifications, however we’re not going to get into the NPU and AI processing modifications at this time. There’s sufficient to speak about simply with the stuff that’ll have an effect on client desktop elements sooner or later (plus the fast impression to laptops).
All of this follows the announcement that NVIDIA is investing in Intel to construct its personal cell components with them later, however there’s no information on that subject at this time. That is all Intel’s {hardware}.
Naming Confusion
Briefly on the naming: Intel admitted its naming mixture of Xe for IP and Alchemist / Battlemage / Celestial / Druid for branding has been complicated. It was cautious to notice that these components aren’t Celestial and the impression we received was that they don’t wish to burn the identify on an incremental enchancment previous to a pending main overhaul. Intel is sticking with “Arc B-Collection” for the Panther Lake cell components, however is shifting to the Xe3 structure. Xe3P will probably be Celestial or desktop components later.
Xe3 IP GPU Block
Intel particularly talked about designing Xe3 to scale to bigger configuration sizes, which might be excellent news for anybody who needs to see one thing higher-end than a B580-class card sooner or later.
Let’s get into micro benchmarks first, then take a look at the block diagram.
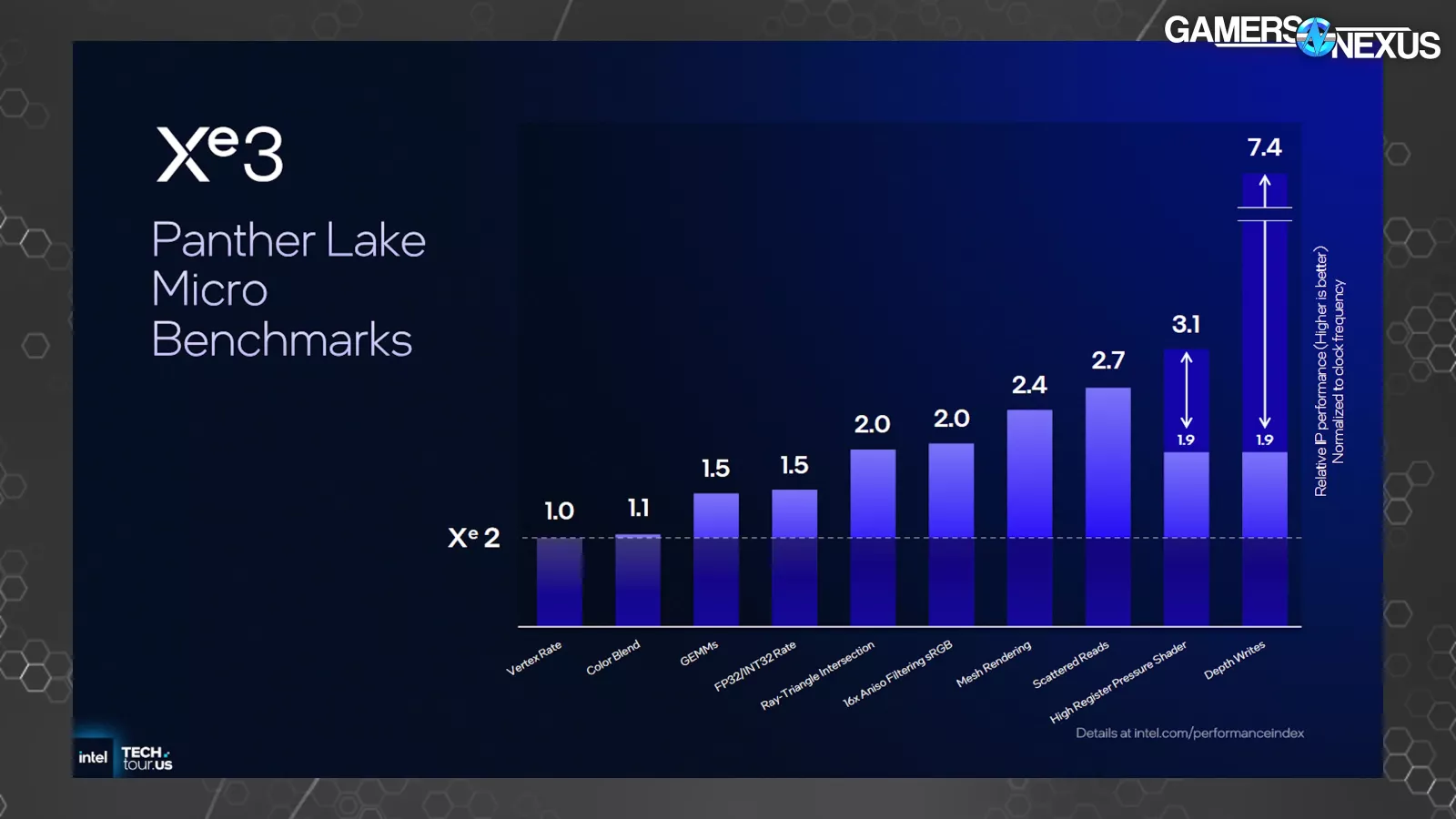
This can be a chart of micro benchmarks, that are workloads designed to focus on extraordinarily particular capabilities or behaviors on a product. A 2x enchancment right here gained’t equal a 2x enchancment in most real-world purposes, however these enable us to see the place the enhancements are showing. Intel revealed these for Xe2 additionally.
In Xe3 for “depth writes,” Intel says it noticed a 7.4x relative efficiency enchancment normalized to clock frequency. We’re not sure, however our understanding is that this isn’t remoted for configuration measurement. Which means this isn’t an ideal comparability for the reason that Xe core depend is completely different between Xe2 and Xe3 in these checks. This 7.4x enchancment outstrips the change in configuration measurement, although.
We requested Intel what “depth writes” means. The corporate informed us that it’s associated to high-Z culling and that this bar represents higher primitives culling within the pipeline, which means culling of unseen triangles and geometry sooner within the pipeline in order to not waste sources rendering unseen objects in-game. An instance may be if a constructing is obstructing a participant — there’s no level rendering the participant if it may well’t be seen. Culling isn’t new and batching primitives in ways in which eradicate occluded primitives has been round without end, however this exhibits that there’s nonetheless loads of floor to realize right here for Intel. It will lead to higher utilization of sources and allocating them to extra productive work. Intel informed us that the advance to this course of is disproportionately helpful, which means that it ought to have an effect in gaming efficiency that will be extra noticeable than different enhancements. We’d anticipate this to hold over to future Celestial dGPU components as properly.
The “Excessive Register Stress Shader” part additionally noticed a big uplift in micro benchmarks at 1.9x to three.1x. Scattered reads improved by 2.7x on the relative scale of time, with Intel noting to us that this has to do with utilizing samplers to learn knowledge scattered throughout one thing like a texture (versus a well-organized knowledge set).
Mesh rendering can also be proven right here, with Intel telling us that Xe2 had already offered a proof of idea round enhancing mesh shading. Intel famous that this micro benchmark is consultant of workloads the place plenty of polygons are current, telling us that the uplift comes from a bigger cache and extra environment friendly use of its registers. Culling additionally contributes.
Shortly, Intel additionally noticed uplift in anisotropic filtering, which is the previous perform that helps enhance smoothness of textures and objects proportionate to the view frustum’s angle. Ray-Triangle intersection additionally improved by 2x within the microbenchmarks on the relative scale, which is noteworthy since Xe2 already benefitted from comparatively giant ray tracing enhancements.
Wanting again on the Xe2 micro benchmarks, Intel then highlighted Draw XI and Compute Dispatch XI primarily. On the time it talked to us about this chart, Intel informed us that this was on account of implementation of native execute oblique assist for oblique draw and dispatch, versus its Xe1 emulation of those capabilities.
Block Diagram

Time to get into block diagrams for the way the brand new Panther Lake Xe3 block is constructed. This exhibits a 12 Xe-core configuration as the utmost measurement introduced for cell, with this configuration carrying 16MB of L2 cache, 2 geometry pipelines, 12 samplers, and 4 pixel backends. The L2 cache is noteworthy right here.

That is the brand new Xe3 render slice. A render slice is Intel’s terminology that defines a block on the GPU containing Xe cores. For reference, the Battlemage B580 with Xe2 has 20 Xe cores on 5 render slices, so every slice is only one a part of the entire GPU.
The Xe2 slice had 4 Xe cores every, with Xe3 shifting to six Xe cores per render slice. Intel additionally intends to scale-up the configuration measurement on cell units to a most of 12 Xe cores (or 2x render slices, up from 8 Xe cores on a previous 2-slice configuration).
The Xe3 render slice exhibits that every Xe core has 8 vector engines, which is unchanged from Xe2 cores; nonetheless, Intel is growing the cache measurement in Xe3. Intel’s Tom Petersen said, “The very first thing we’ve carried out is enhance the dimensions of our L2. By growing the dimensions of the L2 from 8MB to 16MB, we lowered the site visitors that hits the reminiscence interface. That’s necessary as a result of the reminiscence interface is often one of the valuable sources on a graphics chip. We will see anyplace between 17% and 36% site visitors discount heading in the direction of reminiscence, which has a big efficiency impact on these completely different purposes.”
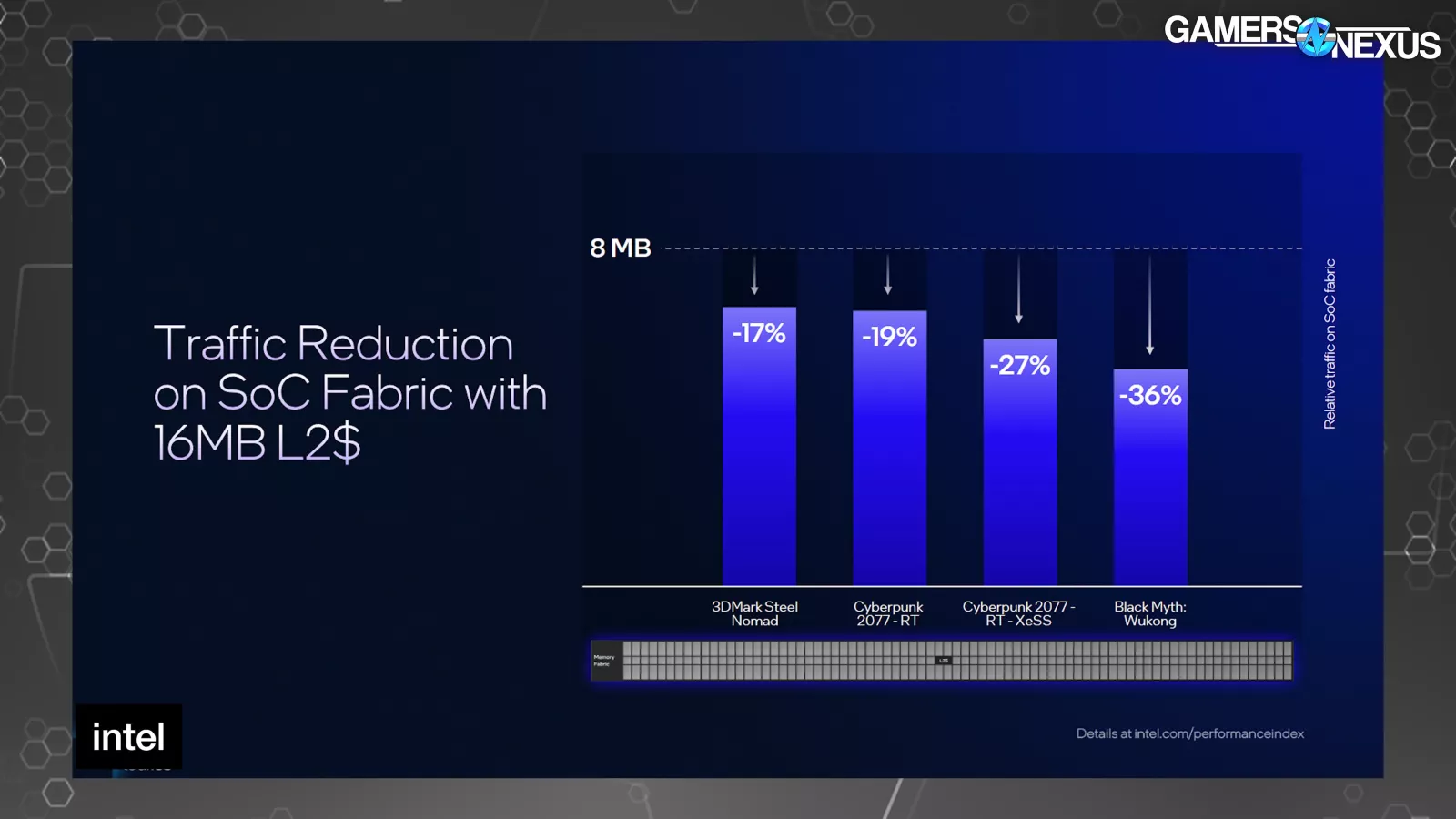
Intel’s first-party outcomes, it presents the advance within the type of relative site visitors on the SoC material (within the vertical axis) in opposition to a baseline 8MB L2 cache. Cyberpunk with RT confirmed a 19% discount, Black Fantasy rasterized confirmed a 36% discount, and the rasterized Metal Nomad take a look at confirmed a 17% discount.

Intel additionally informed us that it has elevated its L1 Cache by 33%, noting a transfer from 192KB to 256KB. Once we requested Tom Petersen which space of uplift he thought had essentially the most impression on total efficiency, he pointed us towards the register and thread modifications. Intel has elevated thread depend upwards of 25% relying on configuration and has moved to variable register allocation. Petersen famous that occupancy of the compute models (together with on Battlemage) beforehand wasn’t at all times excessive, regardless of them being out there for work, which means that there was extra GPU {hardware} current than was being correctly utilized by purposes. Intel has targeted on this in each drivers and {hardware}. He famous that earlier register allocation and thread depend decisions would “starve the pipeline if the shader used too many registers,” which is being addressed.

The ray tracing unit additionally received enhancements. Intel says it “slowed down dispatches of recent rays whereas the sorting unit catches up,” citing out-of-order dispatch and triangle testing. The ray tracing unit enhancements appear to be largely attributed to asynchronous dispatch-test processes.

Intel additionally highlighted a brand new URB supervisor as a part of its fastened perform enhancements, which can also be the place we discover the anisotropic filtering uplift. Petersen said this, “We additionally now have a brand new URB supervisor, which permits partial updates versus flushing the entire thing. Our URB is a construction the place we cross outcomes between our models inside our GPU. It was once considerably of a serializing level; now we are able to really use that partially with out flushing every advanced.”
Body Inspection

We thought these subsequent couple slides have been fairly fascinating as properly:
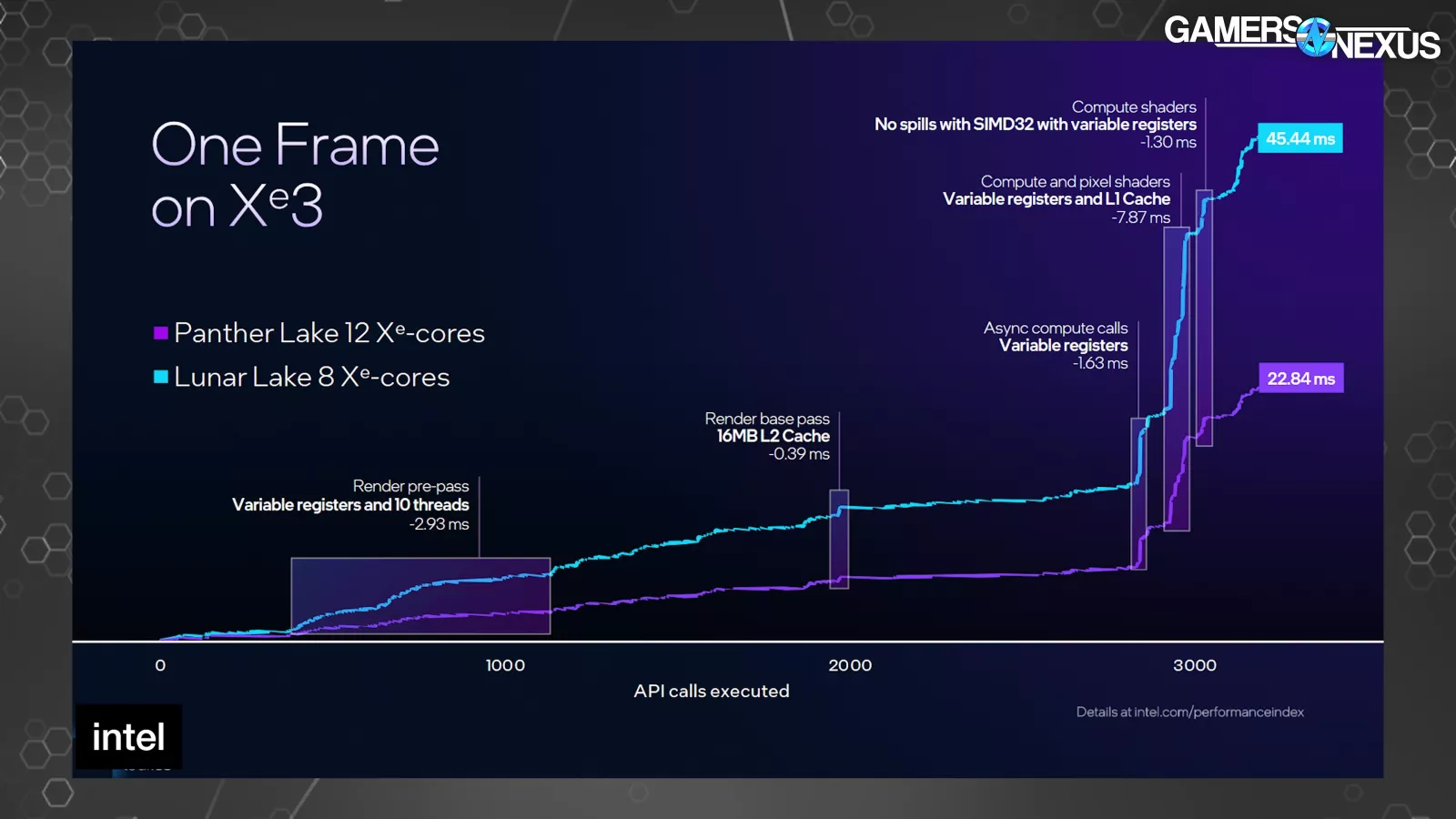
Intel confirmed a body on Xe3 versus Xe2. These aren’t normalized for configuration measurement, so it’s not an ideal comparability and it exhibits a 12-core vs. 8-core configuration, disallowing an ideal like-for-like inspection. That is iso frequency and energy, so it’s not less than normalized there.
The horizontal axis is for API name execution, with the vertical axis being milliseconds of time to execute throughout a single body being drawn (greater is worse). That is for Cyberpunk 2077.
Of word, Intel exhibits an 8ms discount to Xe3 with the compute and pixel shader part towards the top, assigning a few of that uplift to the change to the variable registers and L1 cache measurement enhance. We will additionally see that, in keeping with Intel, the L2 advantages the render base cross with a 0.39ms enchancment, preceded by the transfer to 10 threads (and variable registers) offering a 2.93ms enchancment within the pre-pass.
Extra broadly, Petersen informed us in a name that the register allocation and variety of threads would starve the pipeline if the shader used too many registers beforehand, which is being partially addressed right here. He stated that the earlier structure may trigger a discount within the utilization of accessible compute sources on account of common flushing of the pipeline on account of common reallocation into reminiscence.
This picture is fairly cool and is a take a look at what really occurs in a body when it’s being drawn. We’ve got a full video speaking about this beforehand.
Energy Supply

Intel’s give attention to energy supply and energy administration cites learnings from the MSI Claw (learn our evaluation) units and largely comes within the type of making certain correct useful resource allocation for energy price range between the CPU and GPU, which ought to profit laptop computer and handheld units which have a restricted energy price range cut up between the 2.

Intel famous that beforehand, an absence of utility consciousness meant that the system may generally divert an excessive amount of energy to the CPU, leaving the GPU bottlenecked on its energy restrict whereas the CPU supplied a stage of efficiency that wasn’t being kept-up with by the GPU.

Intel gave the MSI Claw for example of a time this didn’t go properly.
The corporate famous that it improved on this earlier within the 12 months with its Clever Bias Management v2 and is now introducing a v3 to construct upon that.
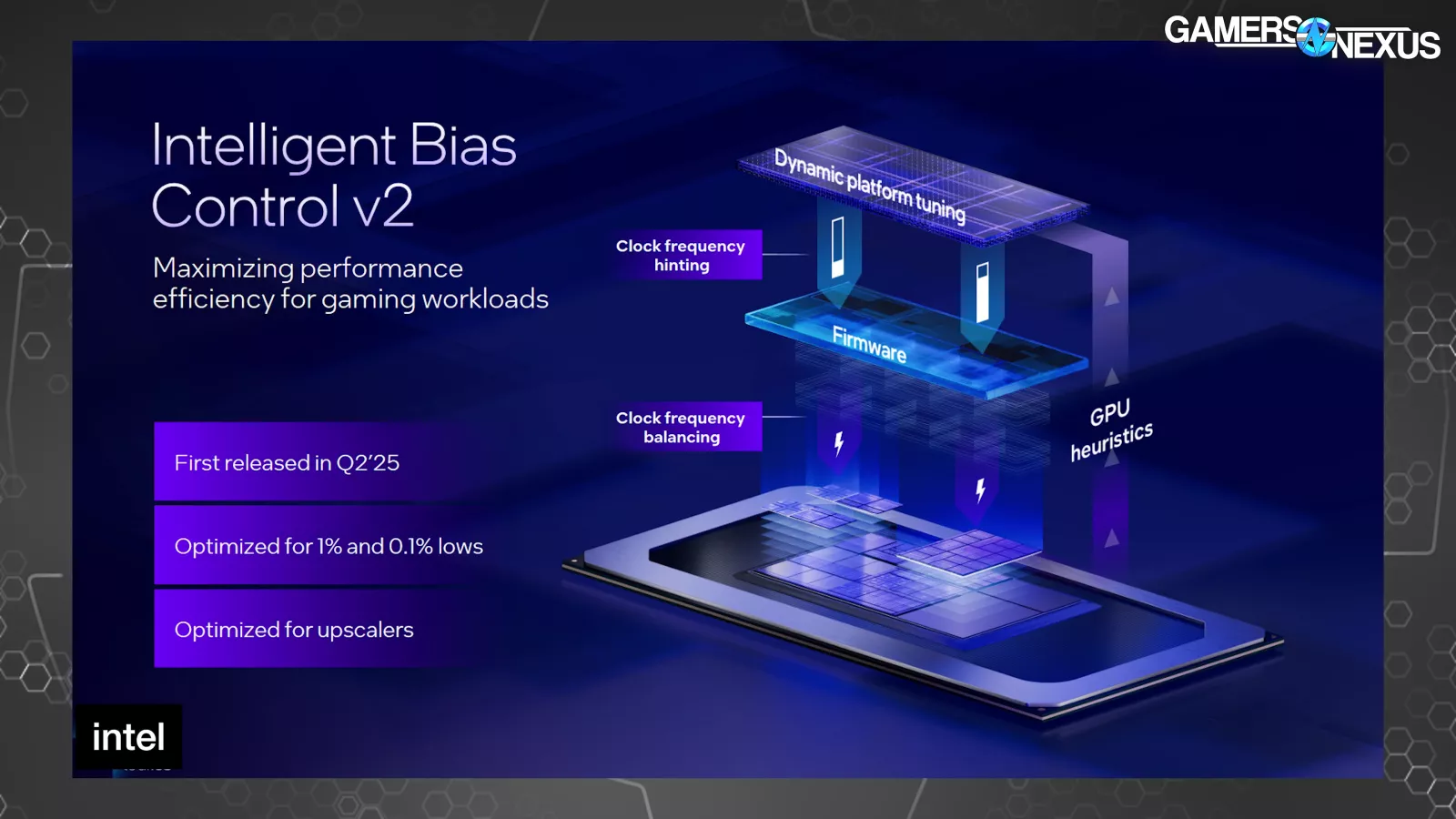
As a result of the system was beforehand unaware of the appliance being run, on this case a sport, Intel stated that software program and {hardware} wouldn’t accurately stability the workload between the CPU and GPU, leading to stuttering on account of being energy starved.
“Clever Bias Management v2” took GPU heuristics and utilization metrics to then inform thread scheduling and useful resource project on the working system-level. Intel had beforehand marketed enhancements to 1% and 0.1% low metrics by way of higher body interval pacing on account of this alteration.
The brand new v3 model of this provides E-core first scheduling, which is self-explanatory in that E-cores get scheduling first when gaming. This sounds worse, and sometimes could be, however Intel says that the top result’s lowered energy diversion to the CPU through the use of decrease energy cores previous to P-cores, freeing-up extra of the shared whole energy price range to go towards the GPU as an alternative. In GPU-bound eventualities, like many video games significantly on handheld units, this can be a higher final result than burning energy on a part that isn’t as burdened.

This comparability between Panther Lake and the prior era of this bias management resolution exhibits that peaks in energy utilization have smoothed-out whereas the GPU energy consumption has leveled to be extra predictable. Reminder: This can be a first-party checks. The GPU can also be getting extra whole energy price range as a share than beforehand, whereas decreasing CPU energy in alternate. For GPU-bound eventualities particularly, this ought to be a greater final result. It would assist in some CPU-bound eventualities as properly.
XeSS Multi-Body Era and Different Modifications
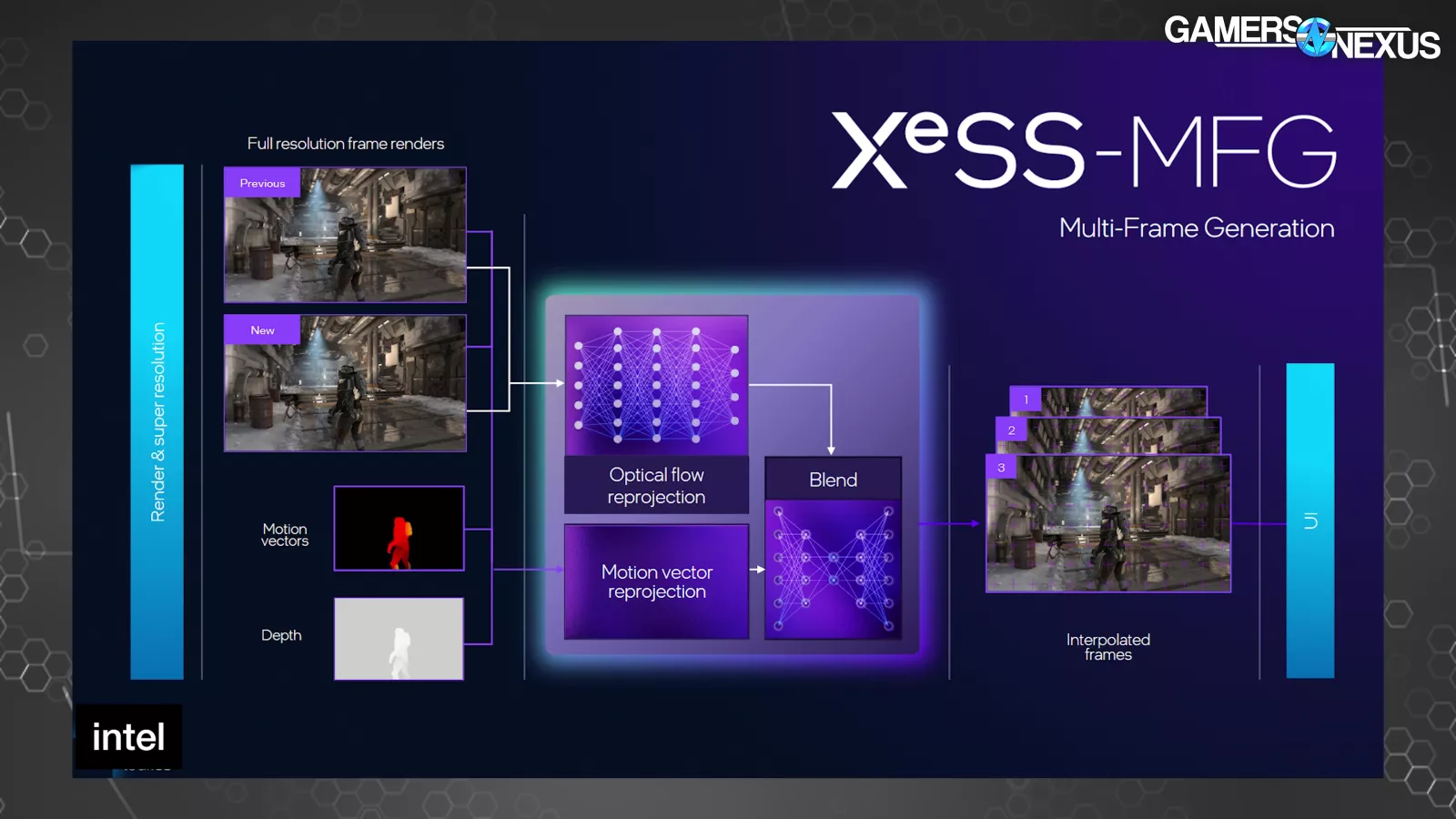
Intel additionally introduced XeSS 3, which incorporates XeSS-Multi-Body Era (or XeSS-MFG). A couple of extra letters and so they’ll have the entire alphabet.
XeSS-MFG is conceptually just like NVIDIA’s MFG. XeSS-MFG takes 2 actual frames to calculate optical stream networks utilizing movement vectors and the depth buffer, then makes use of that info to generate as much as 3 frames between the two actual frames. The frames are then displayed so as and paced in a solution to reduce animation error. We even have a separate deep-dive on our new animation error testing methodology.
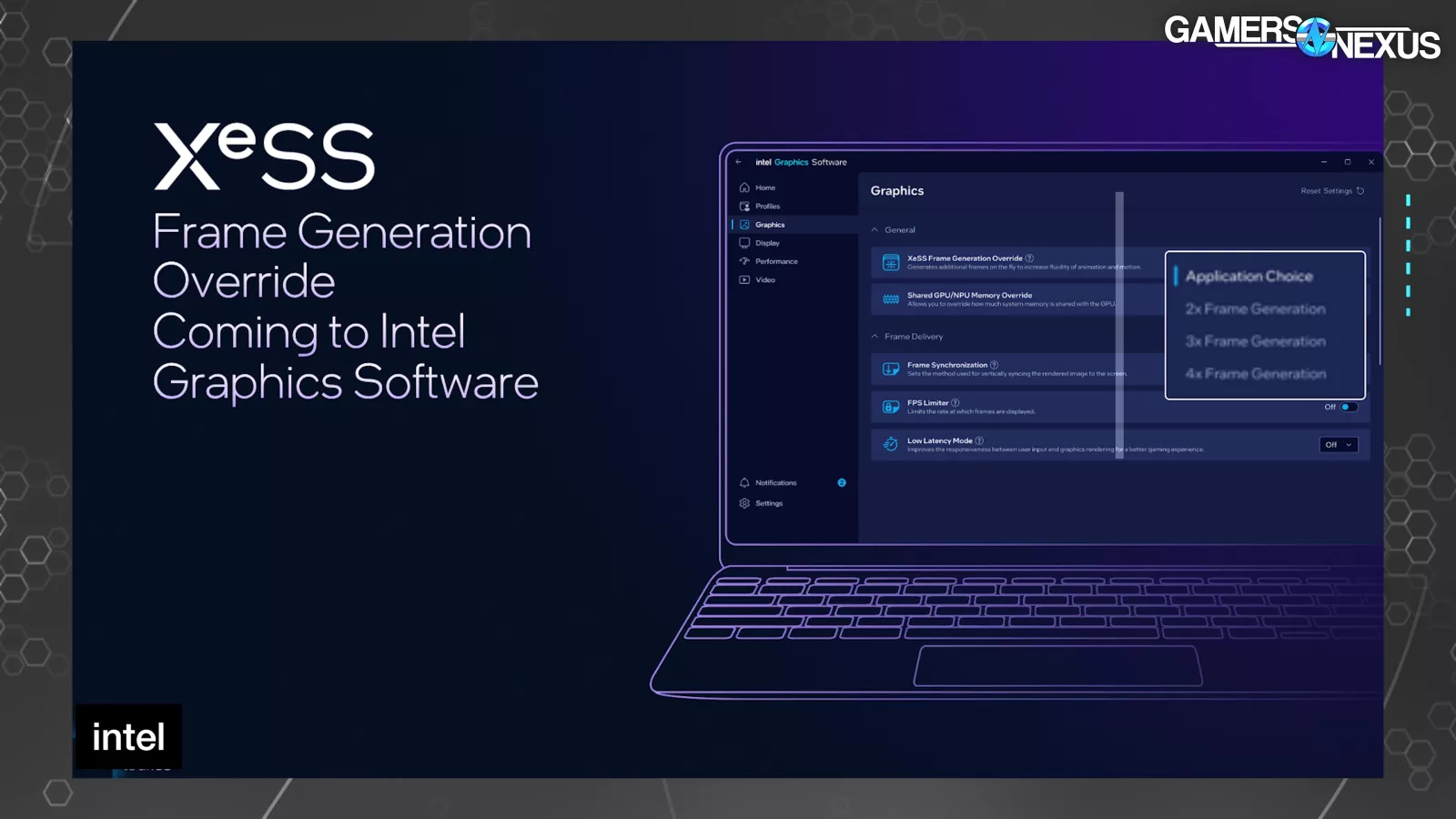
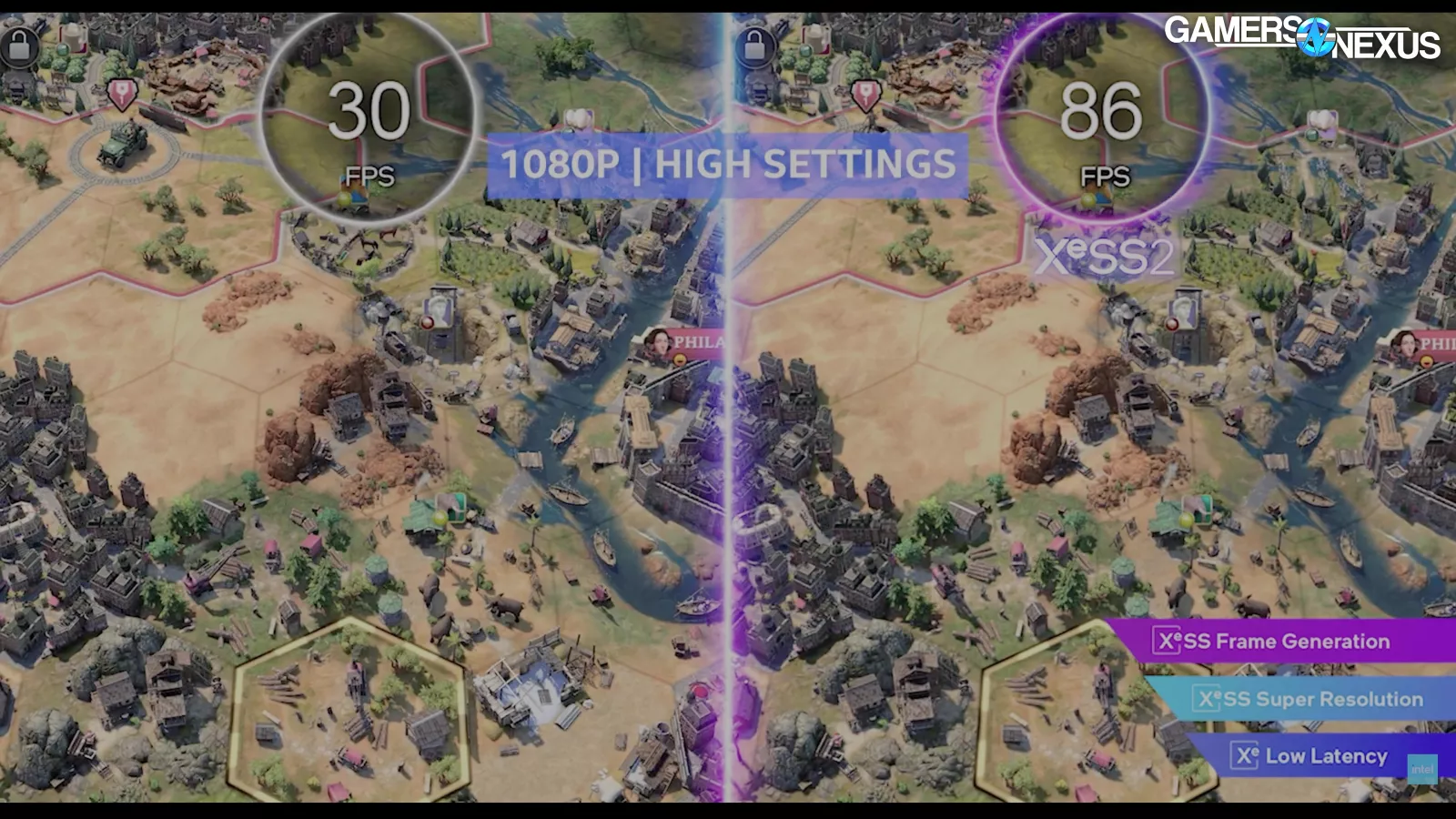
The brand new “XeSS Body Era Override” setting within the driver software program permits the consumer to set 2x, 3x, or 4x mode.
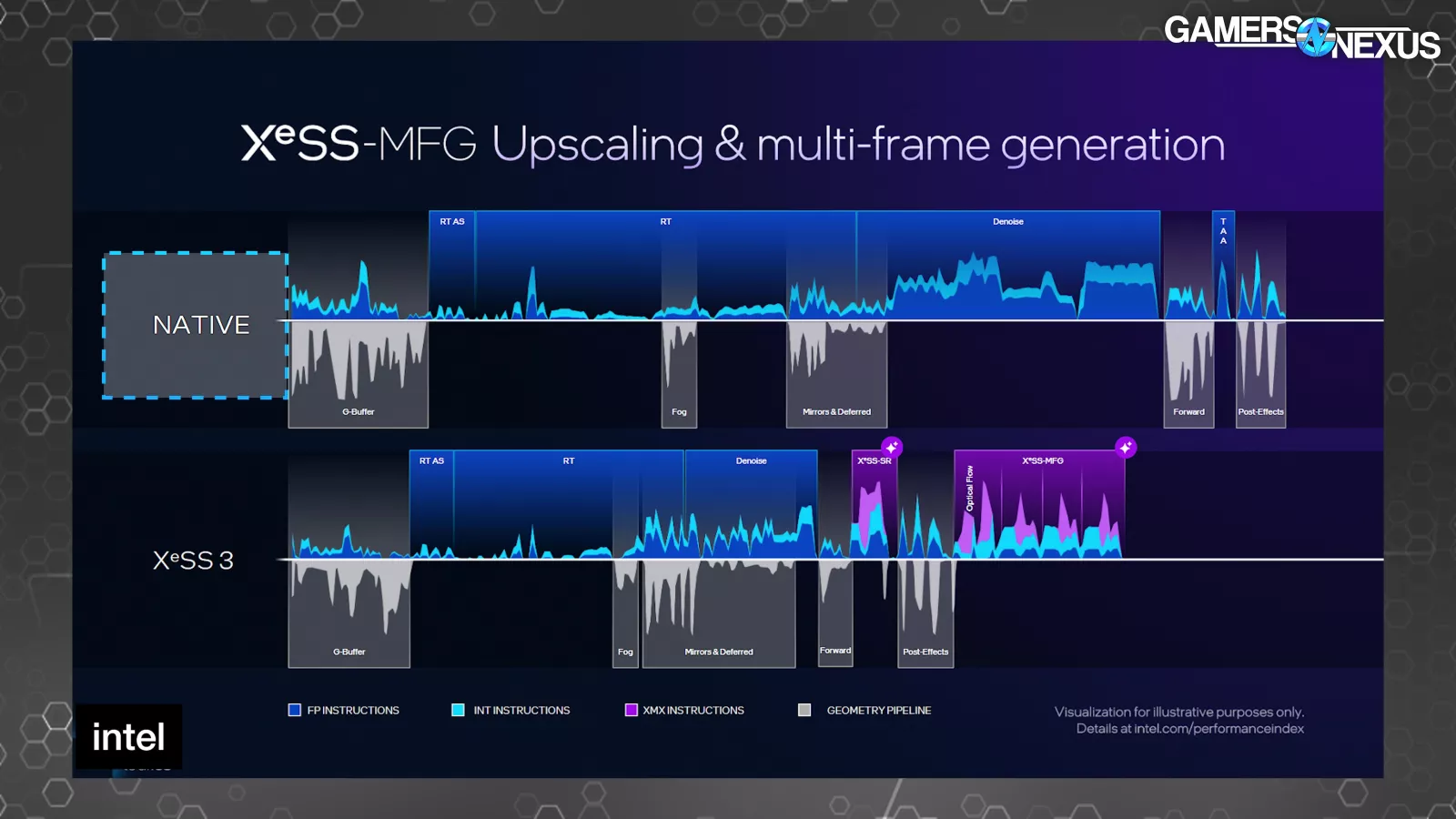
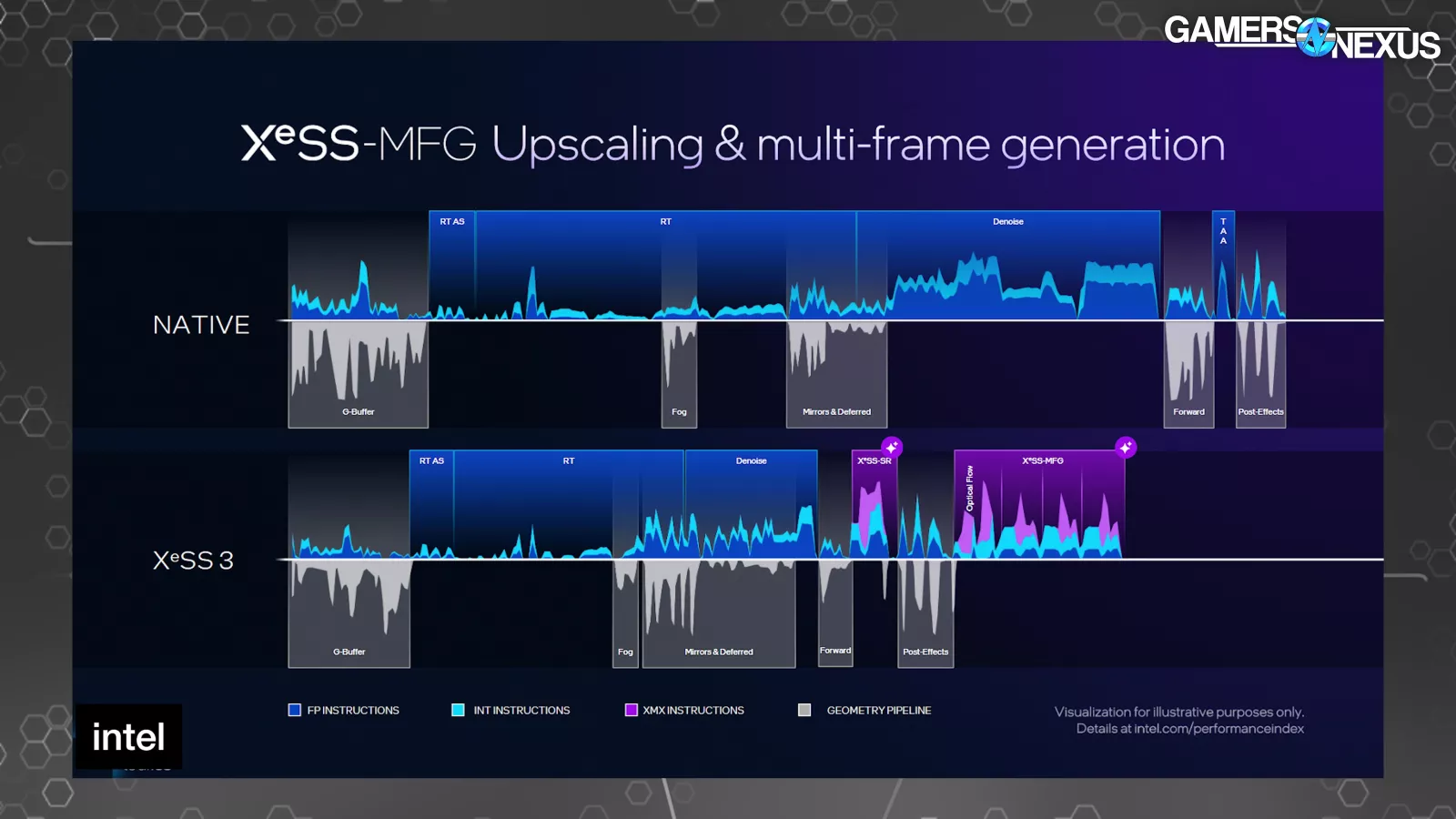
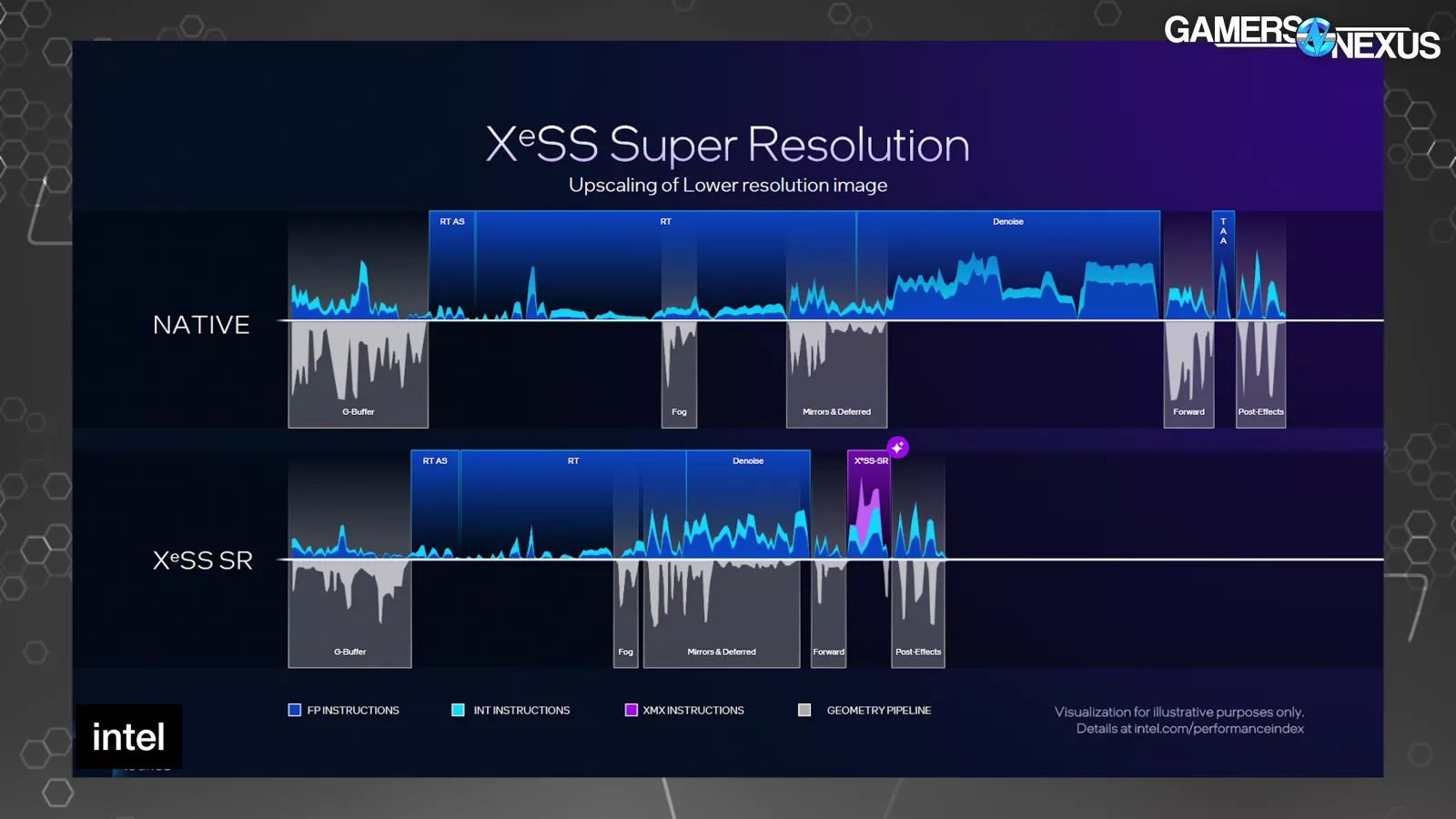
Intel offered a couple of timelines of a single body. One at native, after which a number of with numerous ranges of XeSS know-how in use. The shorter the period that the body is on the X-axis, the much less time the body took to finish. The highest half of every exhibits directions and the underside half exhibits when the geometry pipeline is energetic.
In comparison with native, the raster, RT, and denoise sections of the body are shorter on the XeSS 3 timeline on account of rendering at a decrease decision. The primary purple part represents XeSS-SR to carry out the upscaling. The second purple block begins with the optical stream portion of body gen, adopted by 3 body era operations.

It looks as if Intel’s argument is that your entire body gen course of takes much less time than drawing one actual body, and is subsequently higher or one thing, however this completely ignores picture high quality. We’ve proven with each AMD FMF and NVIDIA MFG that the picture high quality sacrifice isn’t at all times price it. Generally it’s, nevertheless it’s not at all times so simple as being that approach. Intel said that these frames upscaled with XeSS-SR are the identical high quality as native, which is unlikely. Intel said: “That body is pretty much as good because the prior image, the native body. Nevertheless it’s really being run faster.” We doubt this will likely be broadly true and can consider afterward dGPUs. It was bullshit when NVIDIA claimed it, too. The standard might be good, however isn’t pretty much as good.
Intel had another side-by-sides that we take situation with, and that together with nonetheless having watermarks on the video means we’ll skip them and simply take a look at it ourselves later.
Intel referred to the body gen course of as trying into the long run. NVIDIA CEO Jensen Huang has stated related issues about NVIDIA’s body era. Each of them are fallacious, as a result of all present strategies of body era rely totally on completed frames and engine knowledge. These frames already existed and will have been displayed as an alternative of holding them to run the body era in between. That isn’t trying into the long run, that’s interpolating between two sequential snapshots of the current or close to current. Till a predictive methodology of body era comes out, none of those applied sciences look into or generate “the long run,” they at finest interpolate the previous. And that’s superb, however we’d actually prefer it if these firms may get their shit collectively and cease saying that they generate the long run.
MFG represented on benchmark charts has been a serious and ongoing controversy and misrepresentation of efficiency on NVIDIA’s aspect of issues. Intel dedicated to counting on base raster efficiency with out body era because the baseline for efficiency and stated that, when it publishes numbers together with upscaling or body gen, these will likely be offered as supplemental to the bottom metric. We expect this can be a higher stability of selling the potential with out completely misrepresenting the fact.
Intel additionally talked a couple of new model of PresentMon that features a few modifications, partly accounting for body era know-how.